Au障害とOracle RACって、何がそんなにすごいのだろうか

Auに一時的なサービス障害が発生し、社会的に大きな影響が生じた。今回はOracle RACの歴史を紐解きながら、Auのサービス障害を少しだけ解説することにしたい。
Oracle RACの歴史
まずOracle RACというのは、1980年代後半に誕生した一般的なOracle DBよりも少し遅れて、21世紀直前に登場した。複数台のサーバ・コンピュータで一つのDB(データベース)を共有(読み書き)できることが特長だ。
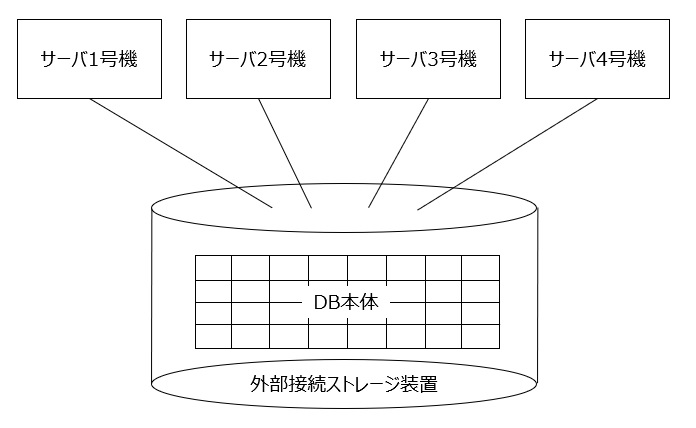
これ、当たり前のように思えるけれども、実は技術的難易度が高い。DB利用者はどのサーバ・コンピュータ上にあるDBプログラムからDB本体へアクセスできるのだけれども、たまたま同じデータを書き換える処理が実行されたら、ちゃんと排他制御されていないと大変なことになってしまう。
もしもあなたが銀行で預金したデータが、何らかの処理でリセットされて預金されなかったことになっていたら、それは大変な問題に違いないだろう。DBにとって排他制御を含む “データ整合性” というのは、実に重要な問題なのである。だからこそ、DBが考案されたという考え方も間違っていない。
さてそれではOracle RACがどのように排他制御を実現したかというと、DB本体を収納する外部接続ストレージ装置に、SCSI3 Persitent Reserveコマンドなるものを実装した。最初にコマンドを発行したサーバがストレージのアクセス権を占有し、解除コマンドを発行したら、どのサーバもアクセス権を獲得できるようになる。
もちろんOracleはDB屋としては優秀だったけれども、当時はストレージ管理の分野で最先端を走っていた訳では無いので、Veritasという会社が技術支援をした。
VeritasはOSベンダよりもストレージ管理に長けており、殆どの業務ITシステムではVeritas Volume Manager (VxVM) とかVeritas File System (VxFS) が採用された。そのVeritasが、複数サーバからのストレージ共有を実現すべく、Veritas Cluster Volume Manager (CVM) とVeritas Cluster File Sytem (CFS) を開発して販売開始した。
これがNFS(ファイル型ストレージ)であればファイル単位でファイルロックが出来るから苦労しないけれども、いかなる時にも安定した高性能を要求されるブロック型ストレージでは技術的課題だったのである。ちなみに初代のOracle RAC (Real Application Cluster) は、Oracle Prallel Serverという名称という名称だった。
ちなみにLinuxが誕生したのは1992年で、企業の業務システムで使えるまで成熟したのは2000年後半頃だ。それまでは各ITベンダが、Unixというオペレーティングシステムを開発していた。
で、Oracleは技術的に相性が良いというか、インターネットに強くてドットコム・バブルで脚光を浴びたSunのSolaris OSが魅力的だったというか、経営者同士が仲良かったというか、ともかくSunのSolaris OSをOracle開発用プラットフォームとして採用していた。
さらに2000年後半にはIBMの名前も挙がったけれども、最終的にOracleがSunを買収することになり、Oracle/Sun連合は強固なものとなった。同時に2006年にはAWSがクラウドサービスを提供開始し、あっという間に売上を伸ばして来た。
そこでOracleとしてはSunハードウェアとOracle DBを一体化させて “ギンギン” にチューニングしたOracle Exadataを製品化した。その性能と使いやすさは折り紙付きで、SalesforceなどのSaaS企業でも採用された。
(まあSalesforceは創業時からOracleと深い関係にあるので、ある意味で当然の選択といえるかもしれない)
Auとの関わり
さて1995年に本格化したインターネットに加えて、2000年に入ると携帯電話の普及が本格化した。2000年後半にはiPhoneなどのスマートフォンが登場し、Auも本格的なシステム更改を迫られるようになった。
今回のAu障害ではネットワーク機器の問題に加えて、加入者DBの不整合問題も言及されている。某社が加入者DBシステムを失注し、2010年に大手SIer(System Integrationベンダー)のCTCさんがOracle Exadata構成で受注した。AuにおけるITシステムの心臓部とも呼べる部分である。
ちなみに加入者DBは2013年にSun Super Clusterへアップグレードされており、これは米国でもプレスリリースが発行され、Yahoo!ファイナンス記事にもなっている。受注したのは今回もSIerのCTCさんである。
- [Yahoo! Finance] KDDI Selects Oracle SuperCluster to Strengthen Authentication System for Mobile Core Network and Support Rapid Data Growth (Jan 24, 2014)
- 移動体コアネットワーク向け認証システムを増強のためKDDIが世界で初めて「Oracle SuperCluster T5-8」を採用(日本オラクル) (2013.10.9)
どうもAuは加入者DBを3G、4G LTE、5Gに分割して保有しているようだ。だから我々がスマホなどでチェックする契約情報は、各DBへデータ提供依頼しているか、契約情報だけを管理する統括DBとでも呼ぶシステムが存在するらしい。
これはちゃんと確認しないと確かなことは言えないけれども、どうやら今回の加入者DBが2013年時点と大きく変わっていなければ、CTCさんがAuと一緒に障害対応に取り組んだということになりそうだ。
(もちろん案件が案件なので、日本Oracleも最大限の支援を提供したことだろう)
まとめ
データベースと言うのはデータ不整合が発生しないように、通常はOLTPなどでトランザクション処理を入れて、データ消失や不整合が生じないように設計されている。
もちろんそれでもデータベース本体がDBサーバやストレージ障害などによってデータ不整合を生じさせるケースは存在し、その時にはDB管理者や専門家が恐ろしい苦労をして回復作業を実施することになる。
そんな訳でAuではVoLTEルーティング機器部分で障害が発生したらしいが、その切り戻しなどによる輻輳で負荷増大し、加入者DBまでやられてしまったと考えられる。
Auは単純に全システムを停止させて復旧作業した訳では無いし、現場の作業は困難を極めただろうと推察される。世間ではAuの対応が遅かったと不満を持つ人が多いらしいが、よく頑張ったものだと評価する。
(今では在来式の固定電話からIP電話へのネットワークが進み、今回のような障害への対応が難しくなっているだろうと推察する)
それでは今回は、この辺で。ではまた。
—————————–
記事作成:小野谷静